Определите, на что влияют размеры буферов
| | |
Здесь приводятся некоторые эвристические правила для задания размеров буферов приема и передачи в TCP. В совете 7 обсуждалось, как задавать эти размеры с помощью функции setsockopt. Теперь вы узнаете, какие значения следует устанавливать.
Необходимо сразу отметить, что выбор правильного размера буфера зависит от приложения. Для интерактивных приложений типа telnet желательно устанавливать небольшой буфер. Этому есть две причины:
Знать размер буфера необходимо для расчета максимальной производительности. Например, это относится к приложениям, которые передают большие объемы данных преимущественно в одном направлении. Далее будут рассматриваться именно такие приложения.
Как правило, для получения максимальной пропускной способности рекомендуется, чтобы размеры буферов приема и передачи были не меньше произведения полосы пропускания на задержку. Как вы увидите, это правильный, но не слишком полезный совет. Прежде чем объяснять причины, разберемся, что представляет собой это произведение и почему размер буферов «правильный».
Вы уже несколько раз встречались с периодом кругового обращения (RTT). Это время, которое требуется пакету на «путешествие» от одного хоста на другой и обратно. Оно и представляет собой множитель «задержки», поскольку определяет время между моментом отправки пакета и подтверждением его получателем. Обычно RTT измеряется в миллисекундах.
Другой множитель в произведении - полоса пропускания (bandwidth). Это количество данных, которое можно передать в единицу времени по данному физическому носителю.
Примечание: Технически это не совсем корректно, но этот термин уже давно используется.
Полоса пропускания измеряется в битах в секунду. Например, для сети Ethernet полоса пропускания (чистая) равна 10 Мбит/с.
Произведение полосы пропускания на задержку BWD вычисляется по формуле:
BWD = bandwidth X RTT.
Если RTT выражается в секундах, то единица измерения BWD будет следующей:
бит
BWD = --------- X секунда = бит.
секунда
Если представить коммуникационный канал как «трубу», то произведение полосы пропускания на задержку - это объем трубы в битах (рис. 3.15), то есть количество данных, которые могут находиться в сети в любой момент времени

Рис. 3.15. Труба емкостью BWD бит
А теперь представим, как выглядит эта труба в установившемся режиме (после завершения алгоритма медленного старта) при массовой передаче данных, занимающей всю доступную полосу пропускания. Отправитель слева на рис. 3.16 заполнил трубу TCP-сегментами и должен ждать, пока сегмент п покинет сеть. Только после этого он сможет послать следующий сегмент. Поскольку в трубе находится столько же сегментов АСК, сколько и сегментов данных, при получении подтверждения на сегмент п - 8 отправитель может заключить, что сегмент п покинул сеть.
Это иллюстрирует феномен самосинхронизации (self-clocking property) TCP-соединения в установившемся режиме [Jacobson 1988]. Полученный сегмент АСК служит сигналом для отправки следующего сегмента данных.
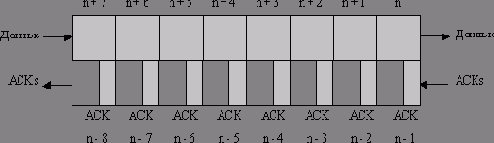
Рис. 3.16. Сеть в установившемся режиме
Примечание: Этот механизм часто называют АСК-таймером (АСК clock).
Если необходимо, чтобы механизм самосинхронизации работал и поддерживал трубу постоянно заполненной, то окно передачи должно быть достаточно велико для обеспечения 16 неподтвержденных сегментов (от п - 8 до п + 7). Это означает, что буфер передачи на вашей стороне и буфер приема на стороне получателя Должны иметь соответствующий размер для хранения 16 сегментов. В общем случае необходимо, чтобы в буфере помещалось столько сегментов, сколько находится в заполненной трубе. Значит, размер буфера должен быть не меньше произведения полосы пропускания на задержку.
Выше было отмечено, что это правило не особенно полезно. Причина в том, что обычно трудно узнать величину этого произведения. Предположим, что вы пишете приложение типа FTP. Насколько велики должны быть буферы приема и передачи? Во время написания программы неясно, какая сеть будет использоваться, а поэтому Неизвестна и ее полоса пропускания. Но даже если это можно узнать во время выполнения, опросив сетевой интерфейс, то остается еще неизвестной величина задержки. ° Принципе, ее можно оценить с помощью какого-нибудь механизма типа ping, но, скорее всего, задержка будет варьироваться в течение существования соединения.
Примечание: Одно из возможных решений этой проблемы предложено в п боте [Semke et al.]. Оно состоит в динамическом изменении па. меров буферов. Авторы замечают, что размер окна перегризк можно рассматривать как оценку произведения полосы пропиг кания на задержку. Подбирая размеры буферов в соответствии с текущим размером окна перегрузки (конечно, применяя подходящее демпфирование и ограничения, обеспечивающие справедливый режим для всех приложений), они сумели получить очень высокую производительность на одновременно установленных соединениях с разными величинами BWD. К сожалению, такоерешение требует изменения в ядре операционной системы, так что прикладному программисту оно недоступно.
Как правило, размер буферов назначают по величине, заданной по умолчанию или большей. Однако ни то, ни другое решение не оптимально. В первом случае может резко снизиться пропускная способность, во втором, как сказано в работе [Semke et al. 1998], - исчерпаны буферы, что приведет к сбою операционной системы.
В отсутствии априорных знаний о среде, в которой будет работать приложение, наверное, лучше всего использовать маленькие буферы для интерактивных приложений и буферы размером 32-64 Кб - для приложений, выполняющих массовую передачу данных. Однако не забывайте, что при работе в высокоскоростных сетях следует задавать намного больший размер буфера, чтобы использовать всю доступную полосу пропускания. В работе [Mahdavi 1997] приводятся некоторые рекомендации по оптимизации настройки стеков TCP/IP.
Есть одно правило, которое легко применять на практике, позволяющее повысить общую производительность во многих реализациях. В работе [Comer and Lin 1995] описывается эксперимент, в ходе которого два хоста были соединены сетью Ethernet в 10 Мбит и сетью ATM в 100 Мбит. Когда использовался размер буфера 16 Кб, в одном и том же сеансе FTP была достигнута производительность 1,313 Мбит/с для Ethernet и только 0,322 Мбит/с для ATM.
В ходе дальнейших исследований авторы обнаружили, что размер буфера, величина MTU (максимальный размер передаваемого блока), максимальный размер сегмента TCP (MSS) и способ передачи данных уровню TCP от слоя сокетов влияли на взаимодействие алгоритма Нейгла и алгоритма отложенного подтверждения (совет 24).
Примечете: MTU (максимальный блок передачи) - это максимальный размер фрейма, который может быть передан по физической сети. Для Ethernet эта величина составляет 1500 байт. Для сети АТМ описанной в работе [Comer and Lin 1995], - 9188 байт.
Хотя эти результаты были получены для локальной сети ATM и конкретно реализации TCP (SunOS 4.1.1), они применимы и к другим сетям и реализациям. Самые важные параметры: величина MTU и способ обмена между сокетами TCP, который в большинстве реализаций, производных от TCP, один и тот же.
Авторы нашли весьма элегантное решение проблемы. Его привлекательность в том, что изменять надо только размер буфера передачи, а размер буфера приема не играет роли. Описанное в работе [Comer and Lin 1995] взаимодействие не имеет места, если размер буфера передачи, по крайней мере, в три раза больше, чем MSS.
Примечание: Смысл этого решения в том, что получателя вынуждают послать информацию об обновлении окна, а, значит, иАСК, предотвращая тем самым откладывание подтверждения и нежелательную интерференцию с алгоритмом Нейгла. Причины обновления информации о размере окна, различны для случаев, когда буфер приема меньше или больше утроенного MSS, но в любом случае обновление посылается.
Поэтому неинтерактивные приложения всегда должны устанавливать буфер приема не менее чем 3 X MSS. Вспомните совет 7, где сказано, что это следует делать до вызова listen или connect.